Enabling Fast Data using in memory-centric computing with Tachyon
Tachyon
“Tachyon is a memory-centric distributed storage system
enabling reliable data sharing at memory-speed across cluster frameworks.”
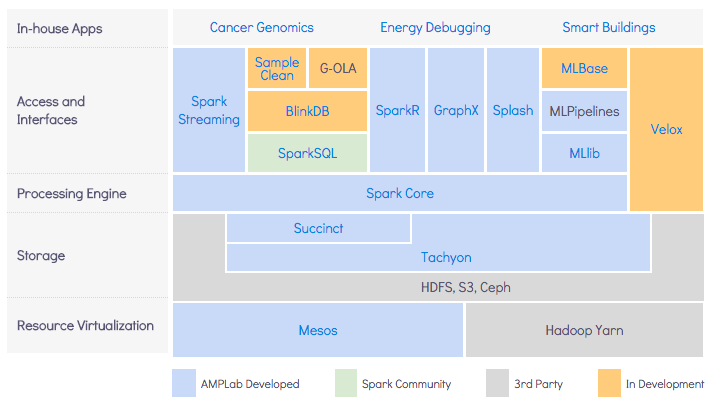
AmpLab BDAS
“BDAS, the Berkeley Data Analytics Stack, is an open source software stack that integrates software
components being built by the AMPLab to make sense of Big Data.”
AmpLab BDAS
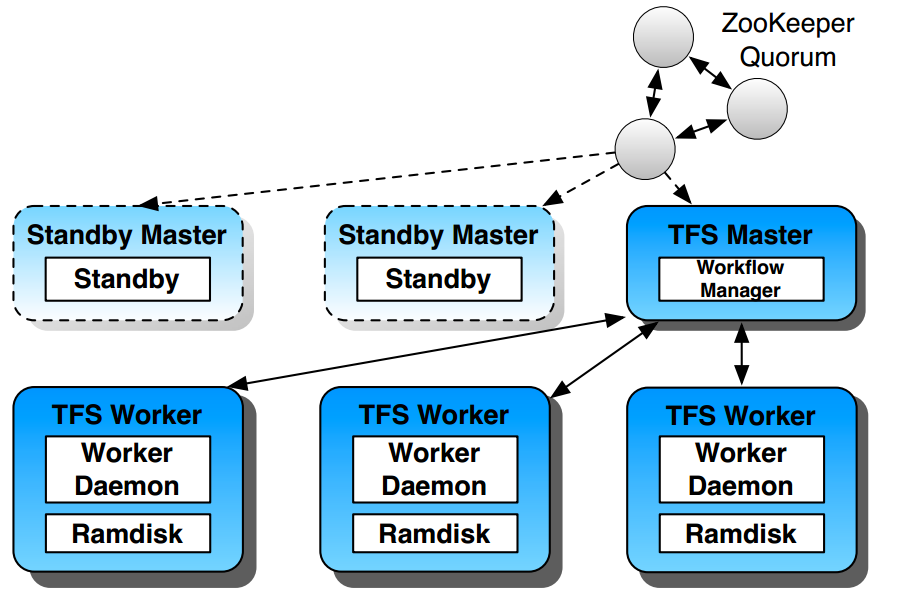
Tachyon architecture
Tachyon architecture
##Storage types
- Tachyon Storage
- multi layer (tiered storage) for storing user files
- may be volatile
- accessible by schema tachyon://[path]
- Underfs storage: 3rd party file system used for persisting tachyon journal, lineage and eventually for user files sync
##Writing Data
When a user writes a new block, it is written to the top tier by default (a custom allocator can be used if the default behavior is not desired). If there is not enough space for the block in the top tier, then the evictor is triggered in order to free space for the new block.
##Reading Data
Tachyon will simply read the block from where it is already stored. If Tachyon is configured with multiple tiers, then the block will not be necessarily read from the top tier, since it could have been moved to a lower tier transparently.
##Block Promotion
Reading data with `TachyonStorageType.PROMOTE` configuration will ensure the data is first transferred to the top tier before it is read from the worker.
This can also be used as a data management strategy by explicitly moving hot data to higher tiers.
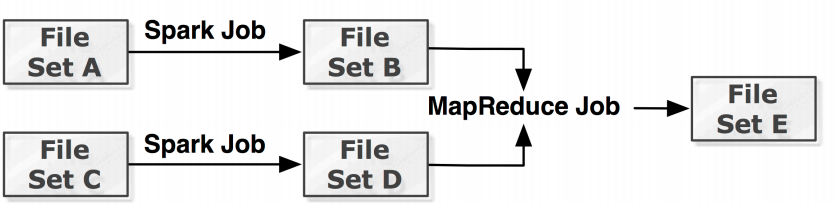
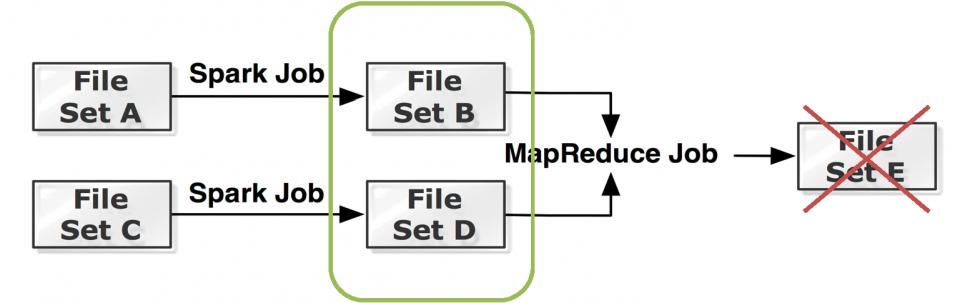
##Lineage
Tachyon can achieve high throughput writes and reads, without compromising fault-tolerance by using Lineage
- lost output is recovered by re-executing the jobs that created the output.
- applications write output into memory, and Tachyon periodically checkpoints the output into the under file system in an asynchronous way.
In case of failures, Tachyon launches job recomputation to restore the lost files.
Lineage assumes that jobs are deterministic.
lineage
##Lineage API (alpha)
```
TachyonLineage tl = TachyonLineage.get();
// input file paths
TachyonURI input1 = new TachyonURI("/inputFile1");
TachyonURI input2 = new TachyonURI("/inputFile2");
List inputFiles = Lists.newArrayList(input1, input2);
// output file paths
TachyonURI output = new TachyonURI("/outputFile");
List outputFiles = Lists.newArrayList(output);
// command-line job
JobConf conf = new JobConf("/tmp/recompute.log");
CommandLineJob job = new CommandLineJob("my-spark-job.sh", conf);
long lineageId = tl.createLineage(inputFiles, outputFiles, job);
```
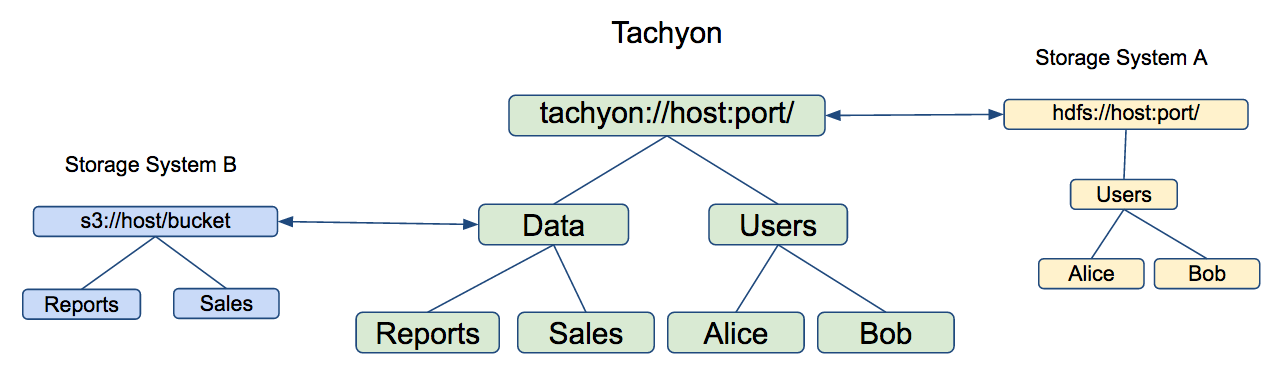
Transparent Naming
Transparent naming maintains an identity between the Tachyon namespace and the underlying storage system namespace.
Unified Namespace
- Tachyon provides a mounting API that makes it possible to use Tachyon to access data across multiple data sources.
##Tachyon shell
- provides basic file system operations (ls, rm, cat, mv, tail, touch etc.)
- provides "special" operation
- persist: persists data from Tachyon storage to the under fs
- pin / unpin: marks / unmarsk a file or folder as pinned in Tachyon (i.e. no eviction will be applied)
- load: load data from under storage into Tachyon storage
- report: marks a file as lost to the Tachyon master. Marking a file as lost will cause the
master to schedule a recomputation job to regenerate the file.
##Remote Write support
```
$ java -cp
SW/tachyon-0.8.2/assembly/target/tachyon-assemblies-0.8.2-jar-with-dependencies.jar
-Dtachyon.master.hostname=backpressure-master
tachyon.shell.TfsShell copyFromLocal icla.pdf /
```
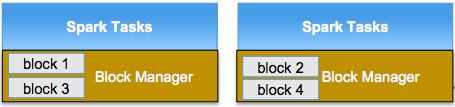
ex. spark memory management
Execution engine
Storage engine
Temporary data and block manager are in the same spark job
GC involved in both of them
Share data between jobs using file system
ex. spark off_heap storage
Execution engine
Storage engine
storage engine stores data in a different process
GC involved only in execution engine
Share data between jobs using Tachyon at memory speed
ex. spark off_heap storage
def persist(newLevel: StorageLevel): this.type
class StorageLevel private(
private var _useDisk: Boolean,
private var _useMemory: Boolean,
private var _useOffHeap: Boolean,
private var _deserialized: Boolean,
private var _replication: Int = 1)